
Recently, there was a conference, and it was mentioned that Base64 encoding, was being replaced with Base32 encoding. The immediate question, is why, especially as Base64 is widely accepted.
The reason for both Base64 and Base32 encoding, is to offer data safety through transportation
Base32 uses more space – a disadvantage
Compared to Base64, Base32 uses roughly 20 % more space however, its main advantage is, that it is more human-readable.
The main reason Base32 is used, is to avoid human error.
UPPER CASE HERE WE COME! – an advantage
One important and simple reason and why Base32 even exists is that it uses A-Z uppercase only (no lowercase) and the numbers 2-7. No 0189. 26 + 6 chars = 32.
There are no lowercase letters and no digits 0189 so “i” “l” “I” and “1” are not confused. There is only I.
Confusion between B and 8, and 0 and O is also eliminated.
If 0 was entered, it can be treated as a O.
But what is clear, the human error non-unique interpretation of the string is reduced significantly. This is not the case with Base64.
All of the above issues with upper and lowercase and numbers being confused all apply to Base64.
Online Base32 encoding
https://emn178.github.io/online-tools/base32_encode.html
Reference
https://stackoverflow.com/questions/50082075/totp-base32-vs-base64
Recently some servers that I look after, had Nessus errors, regarding SSL v3. Yeap. Here it was, some 25 years old, security protocol, still active. The best blog that details how to edit the registry to disable SSL v3 is here:
https://www.namecheap.com/support/knowledgebase/article.aspx/9598/38/disabling-sslv3/
The fix is shown below, as its one of those vulnerabilities, that you edit the registry and then reboot.
A word of caution, the reboot is critical.
Disabling SSLv3
SSLv3 is an obsolete protocol, the main attack vector on which, at the time of writing, is an attack called POODLE. Disabling SSLv3 is the ultimate solution to mitigate security risks. Another option suitable for servers that critically require SSLv3 support is a signalizing TLS_FALLBACK_SCSV cipher suite that allows to keep SSLv3 enabled, but prevents downgrade attacks from higher protocols (TLSv1 =< ). Unfortunately, at the time of writing, Microsoft didn’t yet add support for TLS_FALLBACK_SCSV in SChanel. Therefore, disabling SSLv3 is the only mitigation measure a certificate administrator can apply against POODLE in case of a Windows Server.
- Open registry editor:Win + R >> regedit
- Navigate to:HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\SecurityProviders\Schannel\Protocols\
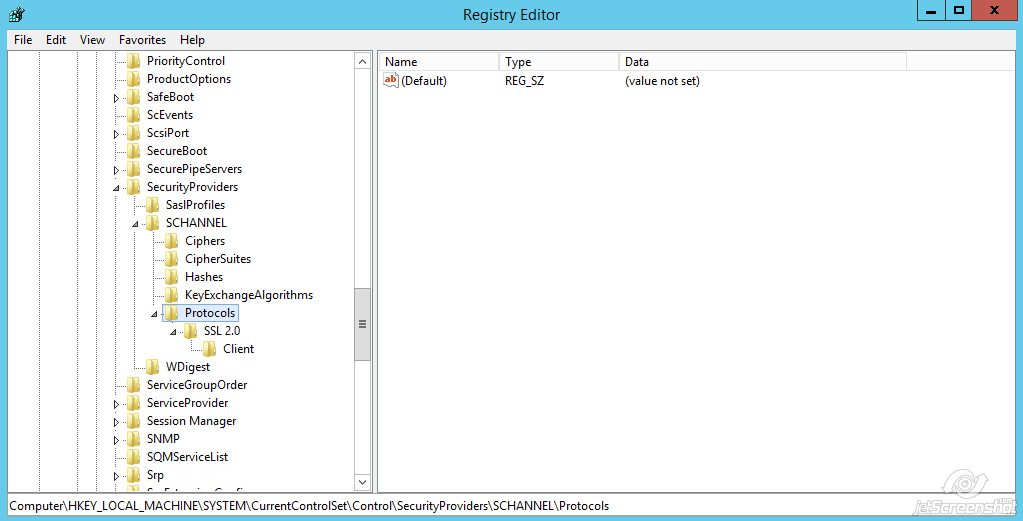
- By default, there should be only one key presented “SSL 2.0”. We need to create a new one for SSLv3Right-click on Protocols >> New >> KeyName the key ‘SSL 3.0’
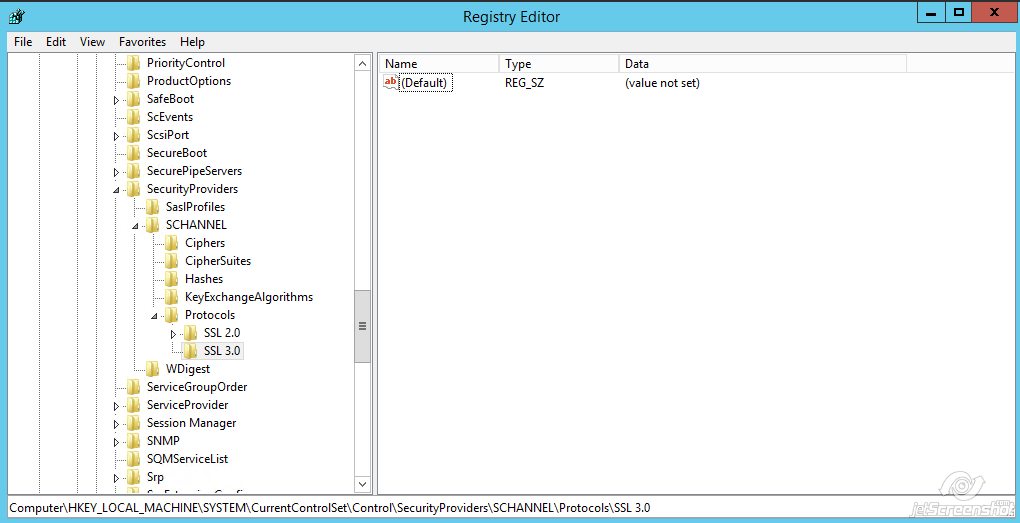
- Right-click on SSL 3.0 >> New >> Key
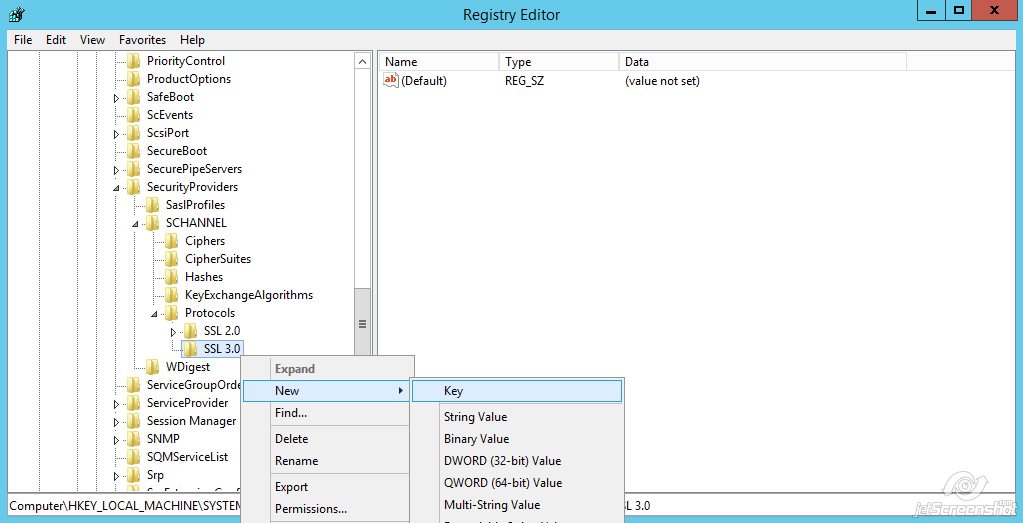 Name the key ‘Server’
Name the key ‘Server’ - Right-click on Server >> New >> DWORD (32-bit) Value
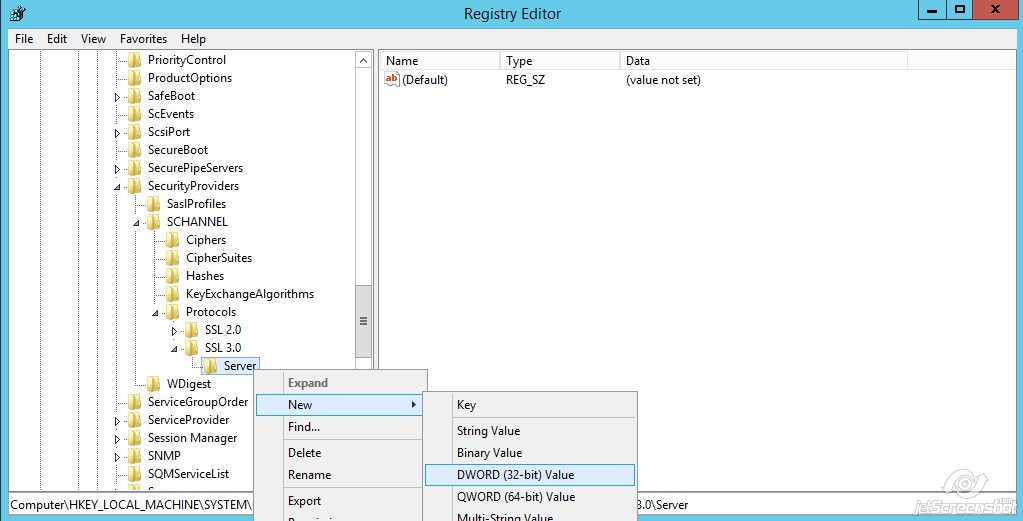 Name the value ‘Enabled‘
Name the value ‘Enabled‘ - Double-click the Enabled value and make sure that there is zero (0) in the Value Data field >> click OK
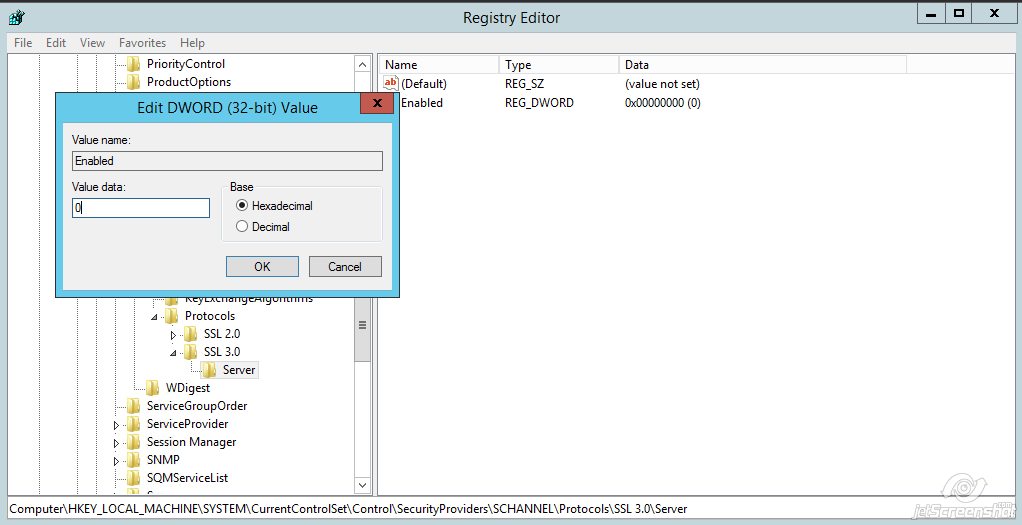
- You may need to restart Windows Server to apply the changes.
SSL v3 was released in 1996, ie 25 years ago.
To disable SSL v2 Client or SSL v3 Client
You’ll need this setting for the client:
SSL 2.0 > client
right click > new key > DisabledByDefault > DWord set to 1

- In the navigation tree, under SSL 3.0, right-click on Client, and in the pop-up menu, click New > DWORD (32-bit) Value.
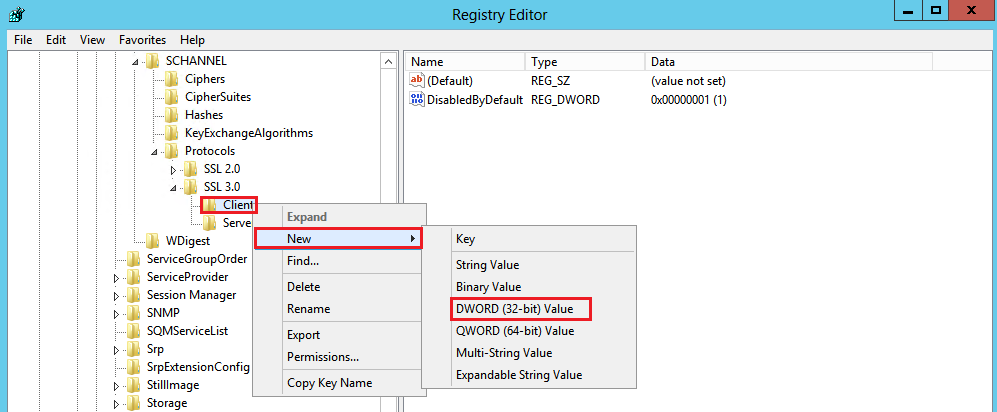
- Name the value DisabledByDefault.
- In the navigation tree, under SSL 3.0, select Client and then, in the right pane, double-click the DisabledByDefault DWORD value.
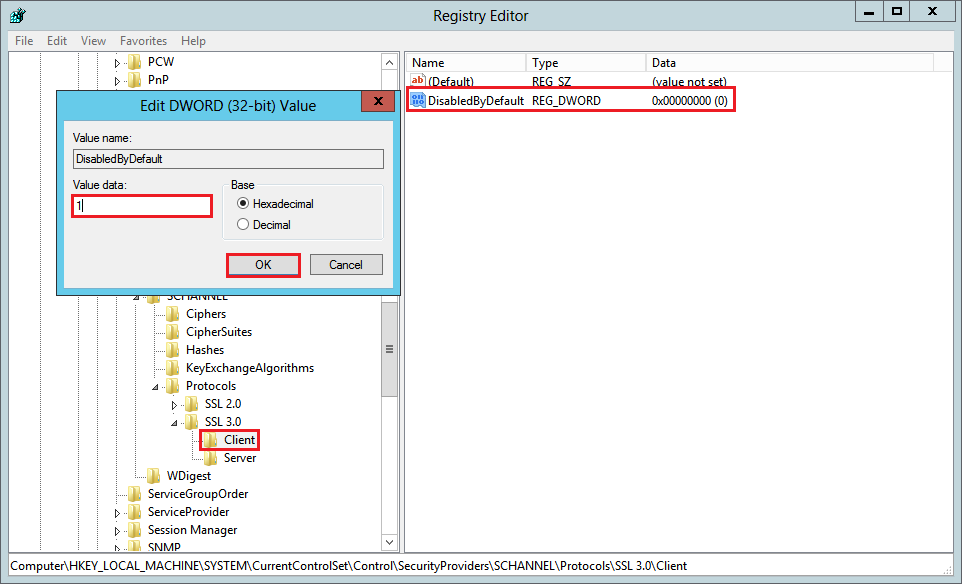
- In the Edit DWORD (32-bit) Value window, in the Value Data box change the value to 1 and then, click OK.
Reference
https://www.namecheap.com/support/knowledgebase
https://www.digicert.com/kb/ssl-support/iis-disabling-ssl-v3.htm
During a SAML exchange, the messages use Base 64 encoding, but what exactly is Base 64 encoding, and what does it look like?
Base 64, means that we use 64 characters in the alphabet, with the 65th character being the = equals sign, which is used to terminate the message.
- Our base 64 alphabet goes from 0 (A in base 64), to 63 (/ in base 64).
- A base 64 sequence will be composed of caracters : A-Z, a-z, 0-9, + and /.
- Base 64 uses a 6 bits representation, because you can represent up to 64 different things with 6 bits Bytes.
- When you convert text to Base 64, it will be first separate into chunks of 24 bits, which is 3 Bytes. Then it will encode each 6 bits of the input with its base 64 value
- If the input’s amount of bits isn’t a multiple of 6, base 64 complete it with 0 bits.
Tools to see the encoding “live”
SAML Tools has a handy text to Base 64 converter, so that we can see the encoding.
Use this tool: https://www.samltool.com/base64.php

The RFC states to add “=” signs to reach the 24 bits multiple (so we can have one or more == signs at the end).
Use this tool: https://md5decrypt.net/en/Conversion-tools/

Both of these tools can take Base64 XML and decode into text, so that you can capture SAML messages and then convert to see the text being sent.

Base64 Character Set – See RFC 4648
RFC 4648 is linked here: https://www.rfc-editor.org/rfc/rfc4648.txt
Advanced stuff:
We can identify the last group of a base 64 sequence by looking for how many equals signs there are, “=” at the end.
The RFC details the 3 scenarios for padding.
RFC 4648 is linked here: https://www.rfc-editor.org/rfc/rfc4648.txt

Base64 Character set

Reference:
https://md5decrypt.net/en/Conversion-tools/
https://www.samltool.com/base64.php
RFC 4648 is linked here: https://www.rfc-editor.org/rfc/rfc4648.txt
The identity management sector, is booming due to Covid, and working from home. There are a few relatively economic certifications in identity management, such as CISM and CAMS that are moving mainstream.
How come I’m promoting Certifications?
Certifications require active recall, and this is the key to success in the real world. The goal is to close your books and quiz yourself, until its easy to recall the answers from memory, under exam conditions. Once you’ve memorised the concepts, you’ll pass the certification, but this intense study, will upskill you across the board. Most importantly, it will give you confidence, that you have mastered IAM’s.
What is one major reason why companies should conduct access audits?
Correct answer: B)
| A) | To avoid fines for noncompliance | |
| B) | To identify potential problems with internal access procedures | |
| C) | To develop an access control matrix |
Periodic access audit will help identify inappropriate access and potential flaws in internal procedures.
What type of access control is currently most popular for businesses?
Correct answer: A)
| | A) | Role-based |
| B) | Identity-based | |
| C) | Discretionary |
Role based access control provides the best access control to ensure access is appropriate.
What do the rows and columns in an access control matrix represent?
Correct answer: A)
| | A) | Subjects and objects |
| B) | Objects and rights | |
| C) | Permissions and users |
Subjects refer to users and objects refer to data that subjects are authorized to access in an access control matrix.
The process allowing authenticated users to access specific information is called what?
Correct answer: A)
| A) | Authorization | |
| B) | Integrity | |
| C) | Identification |
Authenticated users must be authorized to access systems and data.
On which three principles should access control be based?
Correct answer: A)
| A) | Least privilege, separation of duties and need to know | |
| B) | Separation of duties, role within a company and administrative permissions | |
| C) | Need to know, activities within a system and least privilege |
Access should always be granted based on least privilege, separation of duties, and need to know.
How is authentication best defined?
Correct answer: C)
| A) | The way a system recognizes a user | |
| B) | The way a system authorizes a user | |
| C) | The way a user proves who they are |
Authentication is the process by which a system validates a user’s identity.
What is an endpoint?
Correct answer: B)
| A) | A type of malicious attack | |
| B) | A device within a connected network | |
| C) | A security program used to protect against data theft |
Endpoint refers to all devices that connect to a network.
Why is security information and event management (SIEM) essential for data security?
Correct answer: B)
| A) | Ensures compliance | |
| B) | Helps with early detection of suspicious activity | |
| C) | Prevents unauthorized access |
Adequate security information and event management may help detect a breach.
What are the consequences of poor access management?
Correct answer: D)
| A) | Lost productivity | |
| B) | Data Breach | |
| C) | Fines and penalties | |
| D) | All of the above |
Poor access management practices can lead to data breach cases, lost productivity due to data breach investigations, as well as fines and penalties.
What are the three pillars of the AAA triad?
Correct answer: B)
| A) | Auditing, accounting, and authorization | |
| B) | Authentication, authorization, and accounting | |
| C) | Accounting, authenticity, and availability |
Authentication, authorization, and accounting form the basis for the AAA access management model which support the cybersecurity objectives of confidentiality, integrity and availability also known as CIA.
Reference:
I have no links to IMI, nor am I sponsored by them.
This carries on from my earlier OpenSSL post, on how to create a private key. Its assumed that you have created a private key, ready to create the public key.
A certificate is a public key that has been signed by the private key, and in this way it is “certified” or a certificate.
Step 1 – Use the private key to sign a public key, and “certify” it
openssl
req -utf8 -new -key privatekeypem4096.pem -x509 -days 365 -out mycrt.crt

enter the passphrase (ie the password for the private key). This is signing the public key with the private key.
country code – this is a 2 letter code for your country – set by the X509 standards.
state – mandatory in X509 standards
common name – the name of the server or hostname. This site is on domain uwnthesis.wordpress.com.

Step 2 – View the new certifcate file
x509 -in mycrt.crt -text -noout

Who is the Issuer?

This means your private key has been used to sign and certify the public key, called a “Certificate”. The certificate includes:
- Hostname of the server, its for eg uwnthesis.wordpress.com
- Expiry date for the certificate eg 23 Feb 2023
When does this certificate expire?
If you want to check the expiry dates for a certificate, the OpenSSL command would be:
x509 -noout -in mycrt.crt -dates

That’s step 2 complete.
Step 3 is to crete a CSR, or Certificate Signing Request.
More fun
If you want to check your work online, as you have the .pem file, you can upload this to have the data you’ve created checked.
https://www.sslchecker.com/certdecoder
Upload your .pem file.

Issuer

Advanced Reading
When starting to use OpenSSL, the methods and ciphers can seem daunting, so lets break it down. Initially, we always start with the private key. Secondly we create a public key. So lets start with step 1, create a private key, with a symmetric cipher of AES 256. OpenSSL defaults to a *.pem file. We can learn how to convert this to a *.crt later on.
Step 1 – in openssl bin directory (windows)
cd OpenSSL-Win64
cd bin
openssl
genrsa -aes256 -out privatekeypem4096.pem 4096

openssl genrsa -aes256 -out privatekeypem4096.pem (centos linux)

The first prompt is for a passphrase, which is between 4 and 1023 characters long. A passphrase is mandatory.
So what happens if we don’t put it in? You get this error.
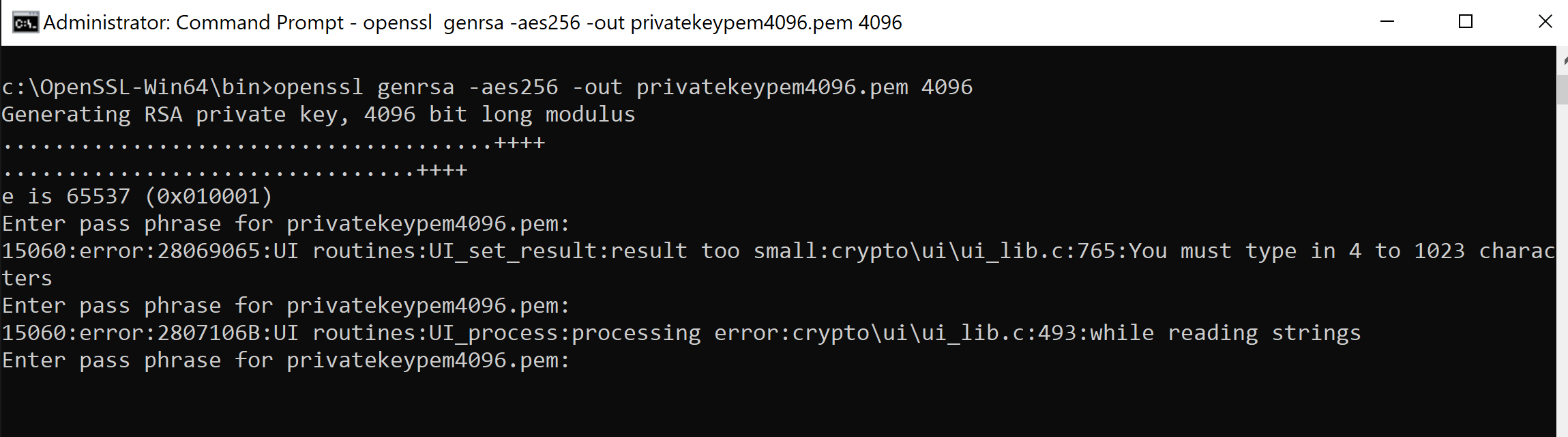
Enter the pass phrase twice. It’s verified.

open the file with notepad or cat to view the contents.
notepad privatekeypem4096.pem

The private key on its own, has to be followed by the creation of the public key, to be useful for signing certficates. So creating the public key is next.
File Formats
PEM – OpenSSL default
DER – Binary format, in ASCII
PKCS#7 – Base64, in ASCII, popular in Windows
PKCS#12 – Binary format, stores keys, certificates
Alternative syntax
The AES cipher is for the symmetric key. The single symmetric key is for high speed encryption/decryption, and needs to be shared by both parties.
genrsa -aes128 -out privatekeypem4096.pem 4096 = AES 128, legacy
genrsa -aes256 -out privatekeypem2048.pem 2048 = AES 256, with 2048 bits public key
genrsa -aes256 -out privatekeypem4096.pem 4096 = AES 256, with 4096 bits public key
Now, you can generate a private key, with various encryption ciphers.
Step 2 – How to create a Certificate or .crt file
OpenSSL : How to create a Certificate .crt
Advanced Reading
To those supporting OAuth, there’s an interesting attack detailed in RFC 7636. In OAuth, the holder of the code, can obtain an access token…. So how does this work?
A public client or native app, allows all applications to view the transactions, therefore a malicious app, can see and swap the code for the Access Token.

Mitigation – PKCE
The use of PKCE (pixie) or Proof Key Code Exchange blocks this attack.
- The device attempting to gain access generates a random string, officially called the code_verifier. code_verifier = the secret. This is transformed to become the code_challenge or t(code_verifier), with the transformation method (t_m).
- This code_challenge is sent to the Authorisation Server, along with the Authorisation Request. Therefore we would see (authn request plus code_verifier hash) being sent together. It stores the code_challenge or t(code_verifier) on the server.
- The Authorisation Server returns the code.
- The client make a call to the token endpoint, and transmits the code plus the code_verifier secret.
- The authorisation server compares the code_verifier secret with t(code_verifier) to ensure they match. If they match, this ensures the device that made the code request, is the device exchanging the code for an access token. If it is a match, an access token is granted.
- The client calls the api using the access token.

Reference:
https://tools.ietf.org/html/rfc7636
Implicit Flow
In Oauth, please don’t use the Implicit Flow. How do we detect a system is using the Implicit Flow?

Check the Browser, for the access_token.

What would been seen if the PKCE code_challenge is being used?

In the browser, this would be visible:

Reference:
Cisco has rolled out fixes for multiple critical vulnerabilities in the web-based management interface of Small Business routers that could potentially allow an unauthenticated, remote attacker to execute arbitrary code as the root user on an affected device.
The flaws — tracked from CVE-2021-1289 through CVE-2021-1295 (CVSS score 9.8) — impact RV160, RV160W, RV260, RV260P, and RV260W VPN routers running a firmware release earlier than Release 1.0.01.02.
Along with the aforementioned three vulnerabilities, patches have also been released for two more arbitrary file write flaws (CVE-2021-1296 and CVE-2021-1297) affecting the same set of VPN routers that could have made it possible for an adversary to overwrite arbitrary files on the vulnerable system.
All the nine security issues were reported to the networking equipment maker by security researcher Takeshi Shiomitsu, who has previously uncovered similar critical flaws in RV110W, RV130W, and RV215W Routers that could be leveraged for remote code execution (RCE) attacks.
While exact specifics of the vulnerabilities are still unclear, Cisco said the flaws —
- CVE-2021-1289, CVE-2021-1290, CVE-2021-1291, CVE-2021-1292, CVE-2021-1293, CVE-2021-1294, and CVE-2021-1295 are a result of improper validation of HTTP requests, allowing an attacker to craft a specially-crafted HTTP request to the web-based management interface and achieve RCE.
- CVE-2021-1296 and CVE-2021-1297 are due to insufficient input validation, permitting an attacker to exploit these flaws using the web-based management interface to upload a file to a location that they should not have access to.
Separately, another set of five glitches (CVE-2021-1314 through CVE-2021-1318) in the web-based management interface of Small Business RV016, RV042, RV042G, RV082, RV320, and RV325 routers could have granted an attacker the ability to inject arbitrary commands on the routers that are executed with root privileges.
Reference
https://thehackernews.com/2021/02/critical-flaws-reported-in-cisco-vpn.html
Here’s an excellent blog on all matters related to IAM, Identity and Access. Cryptography is an important aspect of security. We want high speed and security, and for this, we need to understand new, fast ciphers. There’s more to read here:
https://www.scottbrady91.com/C-Sharp/XChaCha20-Poly1305-dotnet
In this article, I am going to give a high-level overview of ChaCha20, Poly1305, and XChaCha20-Poly1305. This will include some code samples using a libsodium implementation in .NET, and a silly “rolling your own” implementation to help demonstrate the differences between ChaCha20-Poly1305 and XChaCha20-Poly1305.
XChaCha20-Poly1305
XChaCha20-Poly1305 is made up of a few different moving parts, combined to provide an effective encryption algorithm. Let’s take a quick look at their properties and their reason for existing.
💃 ChaCha20
Defined in RFC 8439, ChaCha20 was created as an alternative to AES and is a refinement of Salsa20. While AES may be super-fast thanks to dedicated hardware, ChaCha20 was designed to be a high-speed stream cipher that is faster than AES on software-only implementations. ChaCha20 also acts as a “standby cipher”, offering a viable, widely supported alternative to AES that is ready to use if a weakness in AES is discovered.
ChaCha20 uses a 256-bit (32-byte) key and a 96-bit (12-byte) nonce (aka Initialization Vector). Other variants exist, but that’s the IETF definition.
The ChaCha20 cipher does not use lookup tables (think of the S-box used by AES), is not sensitive to timing attacks, and is designed to provide 256-bit security.
🦜 Poly1305
Again defined in RFC 8439, Poly1305 is a one-time authenticator that takes a 256-bit (32-byte), one-time key, and creates a 128-bit (16-byte) tag for a message (a Message Authentication Code (MAC)).
You can use any keyed function to pseudorandomly generate the one-time key used by Poly1305, including ChaCha20 or AES, by using the key and the nonce to generate the one-time key. The procedure to do this is again defined in RFC 8439.
Unlike HMAC, Poly1305 can only use a key once, meaning the two are not interchangeable.
💃🦜 ChaCha20-Poly1305
Combine the two, and you get the ChaCha20-Poly1305 Authenticated Encryption with Associated Data (AEAD) construct. This construct produces a ciphertext that is the same length as the original plaintext, plus a 128-bit tag.
ChaCha20-Poly1305 is fairly popular; you’ll find implementations in most crypto libraries, such as libsodium and Bouncy Castle, and in use as a TLS ciphersuite.
❎💃🦜 XChaCha20-Poly1305
Unfortunately, ChaCha20-Poly1305’s 96-bit nonce doesn’t lend itself too well to accidental nonce reuse when you start encrypting a large number of messages with the same long-lived key.
eXtended-nonce ChaCha (XChaCha) solves this by taking the existing ChaCha20 cipher suite and extends the nonce from 96-bits (12-bytes) to 192-bits (24-bytes), while also defining an algorithm for calculating a subkey from the nonce and key using HChaCha20, further reducing the security implications of nonce reuse.
By upping the nonce size to 192-bits, the specification author estimates that 2^80 messages can safely be sent using a single key. This reduces the chance of nonce reuse while not sacrificing speed.
While XChaCha20-Poly1305 implementations already exist, it is currently still being standardized. At the time of writing, this draft has expired, so I’m not sure about the status of this specification, or the expired PASETO draft that was waiting for this algorithm to be standardized.
However, using XChaCha20-Poly1305 is perfectly acceptable, and you can see XChaCha20-Poly1305 in use with popular JWT alternatives such as Branca and PASETO in my IdentityModel library.
XChaCha20-Poly1305 in .NET using libsodium
Let’s see how to do this in .NET using libsodium. Libsodium is a popular cryptography library written in C, with wrappers available in many programming languages.
From what I can tell, the most up to date wrapper that works with .NET Core and .NET is libsodium-core. So, let’s install that now.
dotnet add package Sodium.Core
First, you’ll need a 32-byte key. You can bring your own, but for now, let’s new one up using .NET’s cryptographic random number generator:
var key = new byte[32];
RandomNumberGenerator.Create().GetBytes(key);
Next, you’ll need a 24-byte nonce. Again, you can generate this using .NET’s cryptographic random number generator. Libsodium does have its own random number, which in this instance, is available to us through SecretAeadXChaCha20Poly1305.GenerateNonce(). As long you use one of those, I don’t see an issue (XChaCha20 is designed to account for nonce misuse).
var nonce = new byte[24];
RandomNumberGenerator.Create().GetBytes(nonce);
For the final input, you’ll need your plaintext message that you want to encrypt. I’ll use some MF DOOM lyrics.
var message = Encoding.UTF8.GetBytes("Got more soul than a sock with a hole");
And now, you can create the ciphertext.
var ciphertext = SecretAeadXChaCha20Poly1305.Encrypt(plaintext, nonce, key);
This will return a ciphertext with the same length as your plaintext, plus 16-bytes at the end for the tag. Under the hood, this calls libsodium’s crypto_aead_xchacha20poly1305_ietf_encrypt function, which you can read more about in the libsodium documentation.
Decryption is much the same, where we take the ciphertext, the nonce, and the key and call into libsodium’s crypto_aead_xchacha20poly1305_ietf_decrypt function.
var plaintext = SecretAeadXChaCha20Poly1305.Decrypt(ciphertext, nonce, key);
Put it all together in a console app, base64 encode it and you’ll end up with something like this:
Key: hOgkbL66iBftqIRgkVnL9vB7zmxvvbtT2KeW9snWe5k=
Nonce (IV): TC4etSvNDA/8QSEEwjJNAmUd4oVd4f9h
Libsodium Ouput: PTruPyd0yCJza8mdcZS56RHrSmlclCl4GWW9TsO4RoDSbwd4amxgHbsfdU7Kbr4MtJltqW8=
Libsodium Decrypted message: Got more soul than a sock with a hole
Reference:
https://www.scottbrady91.com/C-Sharp/XChaCha20-Poly1305-dotnet
Romanian cybersecurity firm Bitdefender has released a free decryptor for the DarkSide ransomware to allow victims to recover their files without paying a ransom.
DarkSide is a human-operated ransomware that has already earned millions in payouts since it started targeting enterprises in August 2020.
The operation has seen a spike in activity between October and December 2020 when the amount of DarkSide sample submissions on the ID-Ransomware platform more than quadrupled.
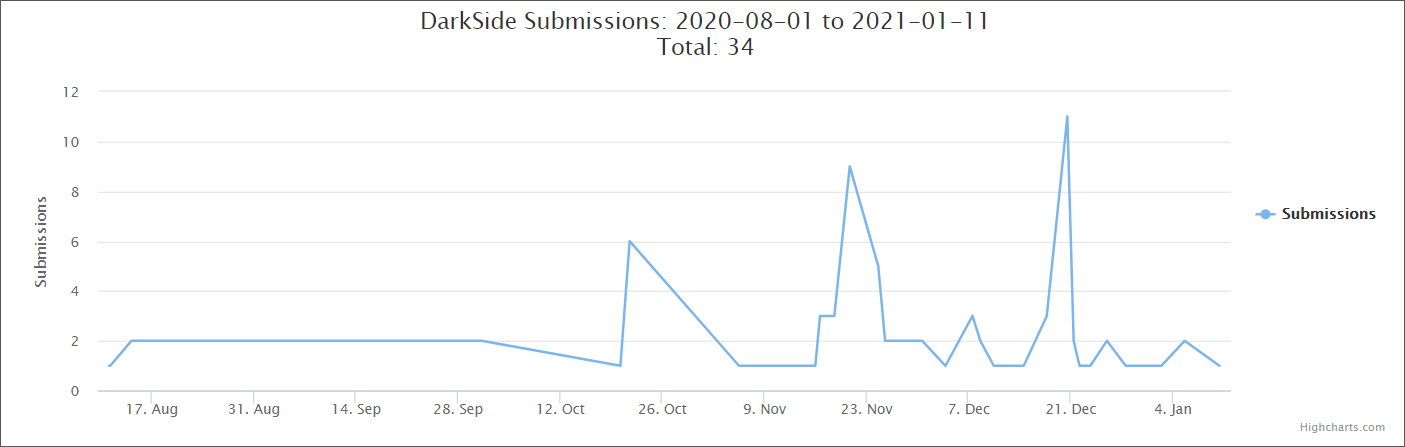
Download the DarkSide decryptor
The DarkSide ransomware decryption tool can be downloaded from BitDefender and it will allow you to scan your entire system or just a single folder for encrypted files.
The decryptor will automatically decrypt all encrypted documents it finds on your computer and, once it’s done, it will remind you to backup your data in the future.
“To remove the encrypted files left behind, you should search for files matching the extension and mass-remove them,” Bitdefender said.
“We do not encourage you to do this until you made sure that your files can be opened safely and there is no damage to the decrypted files.”
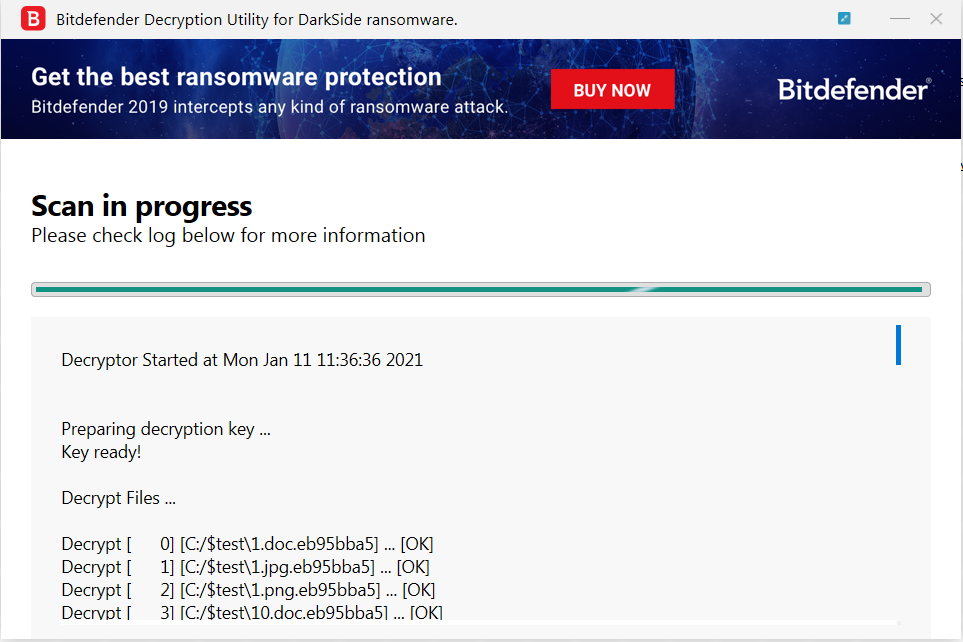
RaaS asks for millions as ransom
DarkSide operates under a ransomware-as-a-service business model and the gang is made out of former affiliates who have already made millions working with other ransomware operations.
After encrypting their victims’ systems, they will charge different amounts depending on the amount of devices encrypted and if they were able to steal data from the victim.
From previous DarkSide attacks documented by BleepingComputer, its ransom demands range from $200,000 to $2,000,000, depending on the size of the compromised organizations.
In November, the DarkSide gang announced that they were building a distributed and sustainable storage system hosted in Iran and in other “unrecognized republics.”
Since the U.S. government has sanctions against Iran, DarkSide ransom payments could be used to pay Iranian hosting providers which could expose victims to fines due to sanction violations.
By hosting some of their servers in Iran, DarkSide’s plans could lead to additional hurdles businesses will have to deal with when deciding if they will pay the ransom.
The release of this free decryptor makes it a lot easier to deal with the aftermath of a DarkSide attack by restoring files on encrypting systems.
Referene:
